
Understanding the Background Processes of PostgreSQL Databases 2024 http://Understanding the Background Processes of PostgreSQL Databases 2024
Introduction

PostgreSQL is an advanced, open-source relational database system known for its reliability, robustness, and performance. Like most relational database systems, PostgreSQL relies on several background processes to manage, maintain, and optimize its operations. These background processes ensure that various tasks, such as data management, replication, and logging, are performed efficiently. This blog provides an in-depth look into these essential background processes of PostgreSQL.
To better understand PostgreSQL, it’s essential to appreciate the intricate architecture that supports its seamless functioning. PostgreSQL, often favored for its extensibility and compliance with SQL standards, operates under a sophisticated system of interconnected components that contribute to its advanced capabilities. One of the key aspects that set PostgreSQL apart is its ability to handle concurrent transactions, support a variety of data types, and execute complex queries with ease.
These background processes in PostgreSQL work cohesively to uphold its ACID (Atomicity, Consistency, Isolation, Durability) properties, ensuring that database transactions are reliable and fault-tolerant. The processes range from managing memory efficiently, handling client connections, maintaining data consistency, to ensuring data is safely written to disk. Understanding these processes not only provides insight into how PostgreSQL maintains high availability and performance but also equips database administrators and developers with the knowledge to troubleshoot and optimize their systems effectively.
This blog aims to delve deeper into the functions and significance of PostgreSQL’s background processes, exploring how each contributes to the overall stability and performance of the database. By doing so, readers can gain a comprehensive understanding of what makes PostgreSQL a preferred choice among enterprises and developers looking for a powerful database solution.
The background processes discussed in this blog will include those related to client handling, memory management, replication, autovacuum operations, checkpointing, and logging, among others. Each section will break down the responsibilities, mechanisms, and potential configuration tips for these processes, offering both theoretical knowledge and practical insights.
Core Background Processes in PostgreSQL
PostgreSQL employs multiple background processes that work collectively to maintain the database. Each process has a specific role that contributes to the overall functioning of the database. Here’s a breakdown of the primary background processes:
1. Postmaster (Master Process)
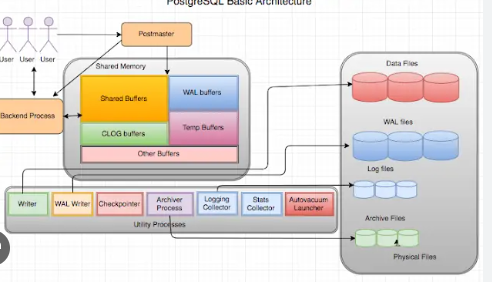
- Role: The postmaster is the central process responsible for the management of the entire PostgreSQL instance. It acts as the parent process and is responsible for handling incoming client connections, starting new backend processes, and managing various auxiliary processes.
- Functions:
- Listening for connection requests from clients.
- Forking new backend processes for client connections.
- Supervising the entire lifecycle of child processes.
2. Backend process
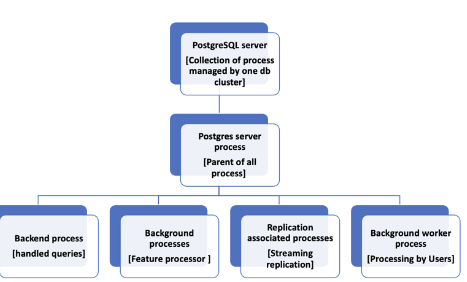
- Role: Each client connection to the PostgreSQL database is managed by a separate backend process. These processes handle the execution of SQL queries, transaction management, and data retrieval.
- Key Points:
- Each connection is isolated to ensure multi-user support.
- The backend process terminates when the client disconnects.
3. WAL Writer Process

- Role: The Write-Ahead Logging (WAL) Writer process is essential for maintaining data integrity and supporting crash recovery. It writes the changes from the WAL buffer to the WAL files on disk.
- Importance:
- Ensures that changes are recorded before they are applied to the actual data files.
- Helps in ensuring durability (the ‘D’ in ACID properties).
4. Checkpointer Process
- Role: The checkpointer process flushes dirty pages (pages modified in memory but not yet written to disk) to the disk periodically. This process reduces the amount of data that needs to be recovered during a crash.
- Key Benefits:
- Prevents excessive I/O load during recovery.
- Improves database performance by ensuring that writes are distributed over time.
5. Background Writer Process
- Role: The background writer supplements the checkpointer process by preemptively writing dirty pages to disk. This helps maintain a consistent balance between memory and disk usage.
- Functions:
- Reduces the load on the checkpointer.
- Contributes to a smoother I/O performance by writing buffers periodically.
6. Autovacuum Daemon
- Role: The autovacuum daemon is responsible for automating the vacuuming process to reclaim storage and prevent data bloat.
- Functions:
- Runs periodically to remove dead tuples from tables.
- Analyzes tables to update statistics for query planning.
- Impact:
- Prevents excessive table bloat.
- Ensures optimal query performance by keeping the database statistics up-to-date.
7. Stats Collector Process
- Role: The stats collector gathers and maintains statistics about the database’s activity and resource usage. This information is essential for query optimization and performance monitoring.
- Details:
- Collects data on table access, number of rows processed, and index usage.
- Sends this information to the pg_stat views, which can be queried by administrators for insights.
8. Logger Process
- Role: The logger process handles the writing of error messages, warnings, and other log entries to log files. This process ensures that logs are separated from main database operations to enhance resilience and performance. The logger process plays a critical role in tracking the behavior of the PostgreSQL server and diagnosing issues.
- Functions:
- Captures and writes information about database operations, errors, and warnings.
- Supports administrators in understanding the flow of queries and system health by providing detailed logs.
- Advantages:
- Enables better monitoring and troubleshooting by recording error details, slow queries, and system warnings.
- Helps maintain an audit trail of activities for security and compliance purposes.
- Facilitates performance optimization by identifying long-running queries and problematic transactions.
- Configuration:
- Logging settings can be configured using parameters like
log_min_messages,log_line_prefix,log_directory, andlog_filename. - PostgreSQL allows for customization of what gets logged (e.g., connections, disconnections, queries) to balance between verbosity and storage concerns.
- Logging settings can be configured using parameters like
- Impact:
- Comprehensive logging supports proactive issue resolution.
- Ensures that any unexpected behaviors or anomalies can be quickly identified and addressed.
By leveraging the logger process effectively, database administrators can maintain transparency over database operations, making it easier to optimize performance and address issues promptly.
Specialized Background Processes
In addition to the core background processes, PostgreSQL has several specialized processes that perform specific tasks, such as replication and maintenance. These processes help improve database scalability, fault tolerance, and performance.
9. Archiver Process
- Role: The archiver process is responsible for copying completed WAL segments to an archive location, which is crucial for Point-In-Time Recovery (PITR) and disaster recovery strategies.
- Functions:
- Ensures that WAL files are preserved for backup purposes.
- Works in conjunction with backup tools to provide comprehensive data protection.
- Impact:
- Enhances data recovery capabilities by maintaining a consistent archive of transaction logs.
10. Replication Processes (WAL Sender and WAL Receiver)
- WAL Sender Process:
- Role: Sends WAL data to standby servers to support streaming replication.
- Functions:
- Streams WAL entries to connected replicas in real-time.
- Helps maintain synchronization between the primary and standby servers.
- WAL Receiver Process:
- Role: Receives WAL data on standby servers and applies it to keep the replica up-to-date.
- Functions:
- Writes incoming WAL data to disk.
- Plays a critical role in maintaining high availability and read scalability.
11. Logical Replication Workers
- Role: These processes are involved in logical replication, which allows for selective replication of individual tables or parts of a database.
- Functions:
- Synchronize specified data between databases.
- Enable complex replication scenarios such as multi-master setups or data warehousing.
- Use Cases:
- Migrating data with minimal downtime.
- Real-time data integration across multiple systems.
12. Logical Decoding Process
- Role: Supports logical decoding, which translates the changes recorded in the WAL into a readable format for external use. This is essential for features like logical replication and change data capture.
- Functions:
- Decodes transactional changes for external streaming.
- Helps applications that need to react to changes in real-time.
How Background Processes Collaborate
PostgreSQL’s background processes do not work in isolation. Instead, they collaborate seamlessly to handle user queries, manage resources, maintain data integrity, and ensure the overall health of the database. Here’s how these processes interact:
- Connection Handling: The postmaster accepts connections and spawns new backend processes for each client, ensuring that resources are allocated appropriately.
- Data Integrity and Recovery: The WAL writer, checkpointer, and archiver collaborate to maintain WAL files and ensure changes are safely logged for crash recovery.
- Performance Optimization: The background writer and autovacuum daemon help maintain performance by balancing memory and disk I/O and reclaiming storage.
- Replication Management: WAL sender and receiver processes, along with logical replication workers, maintain synchronization between the primary and standby databases for high availability and load distribution.
Configuring Background Processes for Optimal Performance
Administrators can tune PostgreSQL’s configuration settings to optimize the behavior of these background processes for their specific use case. Key parameters include:
checkpoint_timeout: Controls how often the checkpointer process runs. Reducing this value can improve crash recovery speed but may increase disk I/O.autovacuumsettings: Parameters likeautovacuum_max_workers,autovacuum_naptime, andautovacuum_vacuum_scale_factorallow fine-tuning of the autovacuum process to manage table bloat effectively.- WAL settings: Parameters such as
wal_level,max_wal_size, andarchive_modeimpact the behavior of WAL-related processes and can be adjusted based on replication needs.
Best Practices for Managing Background Processes
- Monitor Regularly: Use tools like
pg_stat_activity,pg_stat_replication, andpg_stat_archiverto monitor background processes and identify any performance issues. - Adjust Configuration: Fine-tune the parameters based on workload patterns to ensure efficient resource usage and optimal performance.
- Set Up Alerts: Implement monitoring solutions that trigger alerts for abnormal behavior, such as WAL growth exceeding thresholds or replication lag.
- Automate Maintenance: Schedule routine checks and scripts to monitor autovacuum processes and ensure tables are being processed as expected.
Positives:
- Prevents I/O Spikes: By spreading out disk writes, the BgWriter helps maintain a consistent level of I/O activity, preventing performance bottlenecks.
- Enhances Performance: Helps in improving overall database performance by reducing the workload on the main process during peak times.
Negatives:
- Increased Disk Usage: If not configured properly, the BgWriter may lead to excessive disk I/O, which could slow down performance.
- Complex Tuning: Optimizing the BgWriter’s parameters for different workloads requires in-depth knowledge and trial-and-error, which can be time-consuming.
2. Checkpointer Process Role: The Checkpointer periodically writes all dirty pages to disk and creates a checkpoint record in the WAL (Write-Ahead Log). This ensures that the database can recover to a consistent state after a crash.
Positives:
- Improves Recovery: Regular checkpointing enables faster recovery by reducing the number of WAL records that need to be replayed during a crash recovery.
- Data Integrity: Ensures that data is consistently written to disk, maintaining the reliability of the database.
Negatives:
- Performance Impact: Checkpoint operations can cause performance lags, especially if they are triggered during peak load times.
- Configuration Challenges: Finding the optimal checkpoint settings is crucial; frequent checkpoints can lead to higher I/O load, while infrequent ones can slow down recovery.
3. WAL Writer Process Role: The WAL Writer is tasked with writing changes from the WAL buffers to the disk, ensuring data durability and consistency. It operates independently to avoid the main process being bogged down by write operations.
Positives:
- Durability and Reliability: Guarantees that all transactions are safely logged to disk, even before data pages are flushed.
- Independent Operation: Runs separately, ensuring that the primary processes are not delayed by WAL-related activities.
Negatives:
- I/O Contention: Depending on the disk’s capacity, WAL writes can compete with other processes for I/O resources, causing potential slowdowns.
- Latency Sensitivity: Improperly tuned WAL settings might introduce latency, particularly for high-volume write applications.
4. Autovacuum Daemon Role: The Autovacuum Daemon is one of PostgreSQL’s most important background processes, responsible for cleaning up dead tuples and reclaiming storage. It ensures the database remains performant by preventing table bloat.
Positives:
- Automated Maintenance: Autovacuum reduces manual intervention by automating cleanup and optimizing space utilization.
- Prevents Bloat: Helps maintain database health by removing unused data, ensuring queries run efficiently.
Negatives:
- Resource-Intensive: Autovacuum can consume significant resources, impacting query performance if it runs during peak usage times.
- Configuration Complexity: Tuning autovacuum to run at optimal intervals and thresholds can be tricky and may require thorough testing.
5. Stats Collector Process Role: The Stats Collector gathers and monitors statistics about the database’s activity, which helps optimize query plans and provides insights into database performance.
Positives:
- Query Optimization: The statistics collected by this process help the planner make informed decisions, improving query execution times.
- Performance Insights: Allows administrators to monitor and understand database activity for better tuning and scaling.
Negatives:
- Potential Overhead: Collecting statistics can introduce some overhead, especially on large, highly active databases.
- Outdated Stats: In high-transaction environments, there can be delays in updating statistics, leading to suboptimal query plans.
6. Archiver Process Role: The Archiver process is responsible for copying completed WAL segments to a designated archive location. This process is crucial for point-in-time recovery and backup strategies.
Positives:
- Enhanced Data Protection: Archiving WAL segments ensures that data can be restored to any point in time, increasing resilience against data loss.
- Supports Replication: Essential for replication setups, allowing a standby server to sync up with the primary.
Negatives:
Lag Risks: If the archiver fails to keep up with the WAL generation, it could lead to a buildup of segments, potentially causing delays.
Resource Usage: Archiving can consume network and disk resources, especially in high-transaction environments.
Conclusion
Understanding the background processes in PostgreSQL is essential for maintaining a healthy, performant, and resilient database system. Each process plays a significant role in data management, recovery, replication, and maintenance. By effectively configuring and monitoring these processes, database administrators can ensure that their PostgreSQL instances operate at peak efficiency while minimizing the risk of data loss or performance degradation.
Mastering these background processes empowers you to optimize PostgreSQL’s performance, enhance data protection, and support advanced features like replication and high availability, ultimately making you a more effective database administrator.