In this blog post, we’ll explore the essential components of AI Model Deployment and MLOps, focusing on practical implementation and the best tools available, such as TensorFlow Serving, MLflow, Kubeflow, Docker, and Kubernetes. For technical readers, formulas will be provided in a format conducive to easy copying, enabling efficient application to your projects.
1. Introduction to Model Deployment in MLOps
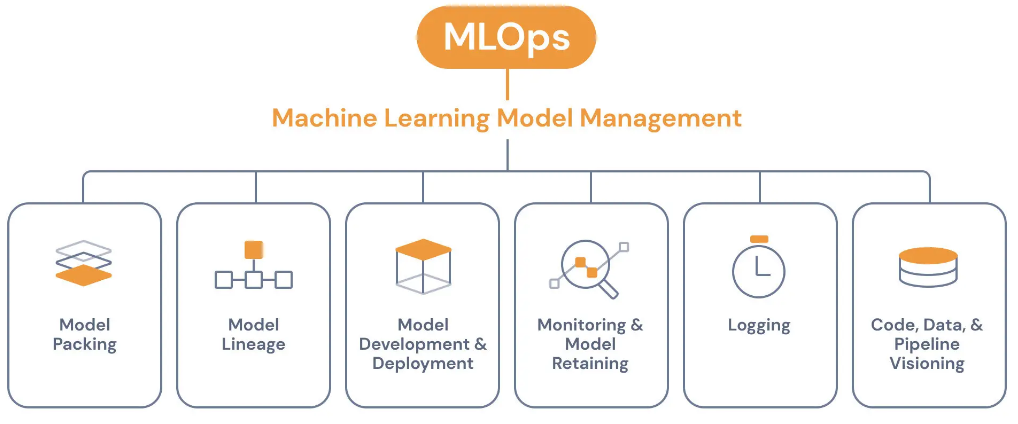
Model deployment is the process of integrating a machine learning model into a production environment to make real-time predictions and interact with other applications. MLOps (Machine Learning Operations) extends DevOps practices to include machine learning workflows, ensuring a reliable and efficient process for model training, deployment, and monitoring.
Key Steps in Model Deployment:
Model Serialization: Save the trained model using formats like TensorFlow .pb files or PyTorch .pt files.
Deployment Environment Setup: Prepare a scalable infrastructure to host the model.
Serving the Model: Utilize tools like TensorFlow Serving or Flask APIs for endpoint management.
Monitoring and Scaling: Ensure that the model is monitored for performance and errors, using tools like Prometheus and Grafana for visualization.
OR
What is Model Deployment?
Model deployment involves making a trained ML model available for use in a production environment where it can deliver real-time predictions or analytics. Deployment bridges the gap between a research environment and a user-facing application.
Key considerations in model deployment:
Scalability: Ensuring the model can handle increasing loads.
Latency: Minimizing the delay between input and output.
Versioning: Keeping track of different model versions.
Security: Protecting the model and data from unauthorized access
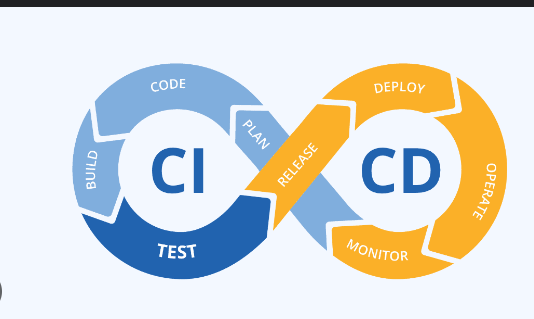
2. CI/CD for Machine Learning
Continuous Integration (CI) and Continuous Deployment (CD) are essential for maintaining seamless workflows in machine learning, from code integration to deployment. CI/CD pipelines automate the process of testing, building, and deploying models, reducing human errors and speeding up releases.
Key Concepts in CI/CD:
Source Control: Use GitHub or GitLab for version control.
Automated Testing: Implement unit tests for model evaluation.
Build Automation: Use Jenkins or GitLab CI/CD for pipeline automation.
Deployment: Deploy models with continuous delivery tools.
OR
Continuous Integration/Continuous Deployment (CI/CD) for ML
CI/CD practices adapt DevOps principles to the machine learning workflow. The goal is to automate the integration of code, testing, and deployment of models to foster an efficient production lifecycle.
Key Components of CI/CD for ML:
Continuous Integration (CI): Automated testing of code and integration with the codebase.
Continuous Deployment (CD): Automatically deploying code to a production environment once it passes all necessary checks.
CI/CD Pipeline Steps:
Code Development: Version control using Git or similar.
Model Training: Training scripts are run, and outputs are validated.
Unit and Integration Testing: Ensuring model quality and compatibility with other system components.
Packaging: Dockerizing the model for consistency and portability.
Deployment: Deploying the model using orchestrators like Kubernetes or services like TensorFlow Serving.
Monitoring and Feedback: Observing performance metrics and retraining as necessary.
Monitoring ensures that the deployed models perform as expected in production. Performance drift, data drift, and concept drift are common issues that may affect models post-deployment.
Monitoring Techniques:
Performance Metrics: Monitoring response times, accuracy, precision, and recall.
Drift Detection: Identifying changes in input data distribution or model performance over time.
Alerting Mechanisms: Setting thresholds to trigger alerts for anomalies.
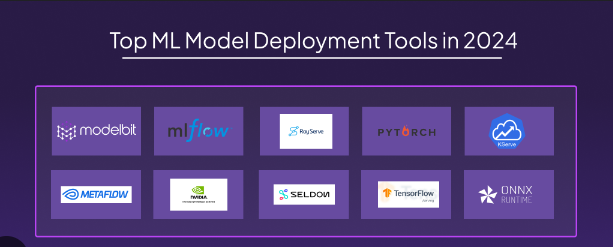
a. TensorFlow Serving
TensorFlow Serving is designed for serving machine learning models efficiently. It can serve multiple versions of a model and supports model versioning and rollback mechanisms.
OR
TensorFlow Serving
Purpose: A flexible and high-performance serving system for machine learning models, especially for TensorFlow models.
Features:
Out-of-the-box support for model versioning.
Automatic model reloading.
Supports gRPC and RESTful APIs for communication.
Deployment: Typically run as a Docker container for ease of scalability and deployment.
Example of a TensorFlow Serving Command:
b. MLflow
MLflow is an open-source platform that helps manage the end-to-end machine learning lifecycle. It provides features like experiment tracking, model versioning, and deployment to various platforms.
OR
MLflow
Purpose: An open-source platform to manage the ML lifecycle, including experimentation, reproducibility, and deployment.
Features:
Supports model tracking and versioning.
Integrates with many ML libraries and can deploy models via REST API.
model = mlflow.sklearn.load_model("models:/my_model/Production") predictions = model.predict(new_data) </pre> c. Kubeflow
Kubeflow is a comprehensive MLOps platform for deploying machine learning workflows on Kubernetes. It supports pipelines for continuous model training and retraining.
OR
Kubeflow
Purpose: A platform that runs on Kubernetes for deploying and managing machine learning models at scale.
Features:
Pipelines for CI/CD.
Integration with Jupyter notebooks for development.
TensorFlow Serving and Seldon Core for serving models.
Deployment Workflow:
Containerize the model using Docker.
Deploy on Kubernetes using Kubeflow’s pipelines.
Kubeflow Pipeline Example:
@dsl.pipeline( name='Simple ML Pipeline', description='A pipeline that trains and deploys a model' ) def simple_pipeline(): train_op = dsl.ContainerOp( name='Train Model', image='gcr.io/my-repo/train-model:latest', arguments=['--epochs', '50'] ) deploy_op = dsl.ContainerOp( name='Deploy Model', image='gcr.io/my-repo/deploy-model:latest' ).after(train_op)
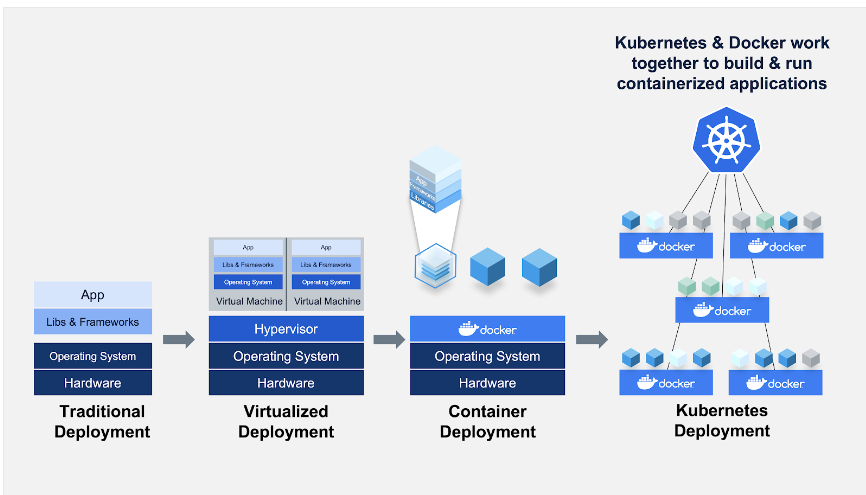
d. Docker and Kubernetes
Docker is essential for containerizing models and their dependencies, ensuring consistent runtime environments. Kubernetes orchestrates these containers for scalable deployments.
Dockerfile Example:
<pre> FROM python:3.9 COPY . /app WORKDIR /app RUN pip install -r requirements.txt CMD ["python", "serve.py"] </pre>
Model monitoring ensures that the performance stays optimal and helps detect data drift or anomalies. Tools like Prometheus for metrics collection and Grafana for visualization are commonly used.
Monitoring Example with Prometheus Metrics:
<pre> from prometheus_client import start_http_server, Summary
@REQUEST_TIME.time() def process_request(request): # Your request processing logic </pre>
5. Combining Tools for a Robust Workflow
Developing and tracking models using MLflow.
Containerizing them with Docker.
Deploying on Kubernetes with TensorFlow Serving or Kubeflow.
Monitoring and scaling using Kubernetes features and integrated tools like Prometheus and Grafana.
Conclusion
Deploying machine learning models with proper MLOps practices ensures a robust and scalable system. Using tools like TensorFlow Serving, MLflow, Kubeflow, Docker, and Kubernetes can streamline the process, while monitoring ensures model longevity and adaptability. Integrating CI/CD practices helps maintain efficient workflows and accelerates model iterations.