
what is computer vision?

Computer vision is a field of artificial intelligence that trains computers to interpret and understand the visual world. By using digital images from cameras and videos and deep learning models, machines can accurately identify and classify objects. This field has revolutionized various industries, from healthcare and automotive to security and entertainment. In this blog, we will dive into four essential subtopics of computer vision: image classification, object detection, image segmentation, and facial recognition.
OR
Computer vision is a field of artificial intelligence (AI) that uses machine learning and neural networks to teach computers and systems to derive meaningful information from digital images, videos and other visual inputs—and to make recommendations or take actions when they see defects or issues.
How does computer vision work?
Computer vision needs lots of data. It runs analyses of data over and over until it discerns distinctions and ultimately recognize images. For example, to train a computer to recognize automobile tires, it needs to be fed vast quantities of tire images and tire-related items to learn the differences and recognize a tire, especially one with no defects.
Two essential technologies are used to accomplish this: a type of machine learning called deep learning and a convolutional neural network (CNN).
Machine learning uses algorithmic models that enable a computer to teach itself about the context of visual data. If enough data is fed through the model, the computer will “look” at the data and teach itself to tell one image from another. Algorithms enable the machine to learn by itself, rather than someone programming it to recognize an image.
A CNN helps a machine learning or deep learning model “look” by breaking images down into pixels that are given tags or labels. It uses the labels to perform convolutions (a mathematical operation on two functions to produce a third function) and makes predictions about what it is “seeing.” The neural network runs convolutions and checks the accuracy of its predictions in a series of iterations until the predictions start to come true. It is then recognizing or seeing images in a way similar to humans.
Much like a human making out an image at a distance, a CNN first discerns hard edges and simple shapes, then fills in information as it runs iterations of its predictions. A CNN is used to understand single images. A recurrent neural network (RNN) is used in a similar way for video applications to help computers understand how pictures in a series of frames are related to one another.
Computer vision examples
Many organizations don’t have the resources to fund computer vision labs and create deep learning models and neural networks. They may also lack the computing power that is required to process huge sets of visual data. Companies such as IBM are helping by offering computer vision software development services. These services deliver pre-built learning models available from the cloud—and also ease demand on computing resources. Users connect to the services through an application programming interface (API) and use them to develop computer vision applications.
IBM has also introduced a computer vision platform that addresses both developmental and computing resource concerns. IBM Maximo® Visual Inspection includes tools that enable subject matter experts to label, train and deploy deep learning vision models—without coding or deep learning expertise. The vision models can be deployed in local data centers, the cloud and edge devices.
While it’s getting easier to obtain resources to develop computer vision applications, an important question to answer early on is: What exactly will these applications do? Understanding and defining specific computer vision tasks can focus and validate projects and applications and make it easier to get started.
Here are a few examples of established computer vision tasks:
- Image classification sees an image and can classify it (a dog, an apple, a person’s face). More precisely, it is able to accurately predict that a given image belongs to a certain class. For example, a social media company might want to use it to automatically identify and segregate objectionable images uploaded by users.
- Object detection can use image classification to identify a certain class of image and then detect and tabulate their appearance in an image or video. Examples include detecting damages on an assembly line or identifying machinery that requires maintenance.
- Object tracking follows or tracks an object once it is detected. This task is often executed with images captured in sequence or real-time video feeds. Autonomous vehicles, for example, need to not only classify and detect objects such as pedestrians, other cars and road infrastructure, they need to track them in motion to avoid collisions and obey traffic laws.7
- Content-based image retrieval uses computer vision to browse, search and retrieve images from large data stores, based on the content of the images rather than metadata tags associated with them. This task can incorporate automatic image annotation that replaces manual image tagging. These tasks can be used for digital asset management systems and can increase the accuracy of search and retrieval.
Here are the brief description of above content
1. Image Classification
What is Image Classification?
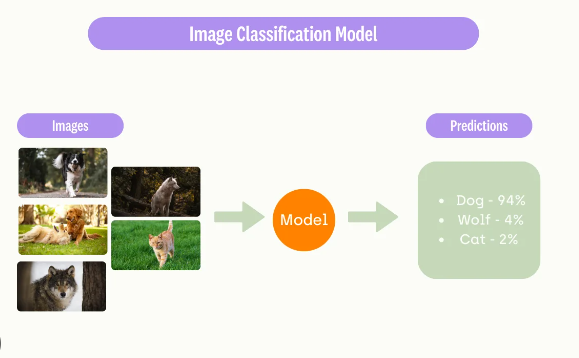
Image classification is the task of assigning a label to an image from a predefined set of categories. It is the most basic and fundamental task in computer vision that serves as the foundation for more complex applications.
How Does Image Classification Work?
Image classification typically involves deep learning models, specifically convolutional neural networks (CNNs), which can capture hierarchical features from an image. These features enable the model to learn patterns such as edges, shapes, and complex structures.
Example Code for a Simple CNN:
Here is a simple code snippet for training an image classification model using Python and TensorFlow:
pythonCopy codeimport tensorflow as tf
from tensorflow.keras import layers, models
# Load and preprocess data
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.cifar10.load_data()
train_images, test_images = train_images / 255.0, test_images / 255.0
# Build the CNN model
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
# Compile the model
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# Train the model
model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
Applications of Image Classification
- Medical diagnostics (e.g., classifying X-rays)
- Content moderation (e.g., detecting inappropriate images)
- Product identification in retail
2. Object Detection
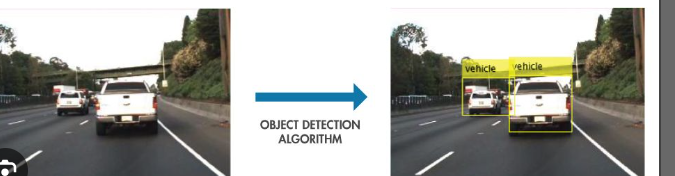
What is Object Detection?
Object detection goes a step further than image classification by identifying and locating objects within an image. This allows not only recognition but also the detection of the position of various objects using bounding boxes.
Popular Algorithms for Object Detection
- YOLO (You Only Look Once): A real-time object detection system that processes images in one go.
- SSD (Single Shot Multibox Detector): Balances speed and accuracy.
- R-CNN (Region-based Convolutional Neural Networks): Breaks down the task by first proposing regions and then classifying them.
Example Code Using YOLOv5:
You can use the popular ultralytics/yolov5 library to implement object detection:
pythonCopy code!pip install ultralytics
from ultralytics import YOLO
# Load the pre-trained model
model = YOLO('yolov5s.pt')
# Run inference on an image
results = model('example_image.jpg')
# Display results
results.show()
Applications of Object Detection
- Self-driving cars (e.g., detecting pedestrians and other vehicles)
- Surveillance systems
- Real-time sports analysis
3. Image Segmentation

What is Image Segmentation?
Image segmentation involves partitioning an image into multiple segments or regions to simplify the analysis. This technique helps identify the boundaries and structure of objects within an image.
Types of Image Segmentation
- Semantic Segmentation: Classifies each pixel into a category (e.g., road, sky, building).
- Instance Segmentation: Detects and delineates individual objects within the same category.
- Panoptic Segmentation: Combines semantic and instance segmentation for comprehensive analysis.
Example Code for Semantic Segmentation Using U-Net:
U-Net is a popular architecture for image segmentation tasks:
pythonCopy codefrom tensorflow.keras import layers, models
def unet_model(input_shape=(128, 128, 3)):
inputs = layers.Input(input_shape)
# Encoder
c1 = layers.Conv2D(64, (3, 3), activation='relu', padding='same')(inputs)
c1 = layers.Conv2D(64, (3, 3), activation='relu', padding='same')(c1)
p1 = layers.MaxPooling2D((2, 2))(c1)
# Decoder
u1 = layers.Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(p1)
u1 = layers.concatenate([u1, c1])
outputs = layers.Conv2D(1, (1, 1), activation='sigmoid')(u1)
return models.Model(inputs, outputs)
model = unet_model()
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
Applications of Image Segmentation
- Medical imaging (e.g., segmenting tumors)
- Autonomous driving (e.g., road and lane detection)
- Satellite image analysis
4. Facial Recognition
What is Facial Recognition?
Facial recognition is a biometric technology that identifies or verifies a person by analyzing their facial features. This technology has become prominent in security, authentication, and social media.
How Facial Recognition Works
Facial recognition typically involves the following steps:
- Face Detection: Identifying faces within an image.
- Feature Extraction: Extracting distinct facial features using techniques like the Dlib library or CNNs.
- Face Matching: Comparing the extracted features with stored data for recognition or verification.
Example Code Using OpenCV and Dlib:
Below is a simplified version of face detection using OpenCV:
pythonCopy codeimport cv2
# Load the pre-trained face detection model
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# Read the image
image = cv2.imread('example_image.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Detect faces
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
# Draw bounding boxes
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x + w, y + h), (255, 0, 0), 2)
cv2.imshow('Image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
Applications of Facial Recognition
- Security and surveillance (e.g., identifying criminals)
- Mobile device authentication (e.g., Face ID)
- Personalized user experiences in social media
Conclusion
Computer vision is a rapidly evolving field with a broad range of applications that improve efficiency and user experience across industries. Image classification, object detection, image segmentation, and facial recognition each play unique roles in this field, supported by powerful algorithms and models. As technology advances, the capabilities of computer vision systems are expected to become even more sophisticated and widespread.