Introduction

Deep Learning: The Brain Behind Modern AI 2024
Deep Learning has emerged as a pivotal field in artificial intelligence (AI), enabling breakthroughs in a myriad of domains such as computer vision, natural language processing (NLP), speech recognition, and more. This blog will explore the intricacies of Deep Learning, its components, architecture, applications, and future trends.
1. What is Deep Learning?

Deep Learning is a subset of machine learning that seeks to simulate the way the human brain works to process data and create patterns for decision-making. Unlike traditional machine learning algorithms, which often rely on structured data and require manual feature extraction, deep learning leverages artificial neural networks (ANNs) with multiple layers to automatically learn representations from raw data. This capability has propelled AI to new heights, enabling advancements in fields such as computer vision, natural language processing (NLP), robotics, and healthcare.
Deep Learning is a subset of machine learning that seeks to simulate the way the human brain works to process data and create patterns for decision-making. Unlike traditional machine learning algorithms, which often rely on structured data and require manual feature extraction, deep learning leverages artificial neural networks (ANNs) with multiple layers to automatically learn representations from raw data. This capability has propelled AI to new heights, enabling advancements in fields such as computer vision, natural language processing (NLP), robotics, and healthcare.
How deep learning works
Deep learning works by using artificial neural networks to simulate how the human brain processes information. These networks consist of layers of interconnected nodes (neurons) that process data through mathematical transformations. The basic structure includes:
- Input Layer: The first layer that receives the input data.
- Hidden Layers: One or more layers where data is processed through various mathematical operations. The term “deep” in deep learning refers to the multiple hidden layers in these networks.
- Output Layer: The final layer that outputs the result of the network’s processing.
Each connection between neurons has a weight that influences the signal strength, and an activation function introduces non-linearity, allowing the network to learn complex patterns.
The learning process involves:
- Forward Pass: Data flows from input to output, generating predictions.
- Loss Calculation: A loss function measures the difference between the predicted and actual values.
- Backpropagation: The error is propagated back through the network, adjusting the weights to minimize the loss using optimization algorithms like gradient descent.
- Iteration: This process repeats until the model achieves a satisfactory level of accuracy.
Deep learning’s multiple hidden layers enable it to learn intricate patterns and representations from large, unstructured datasets, making it powerful for tasks such as image recognition, natural language processing, and more.
Types of deep learning models
Deep learning algorithms are incredibly complex, and there are different types of neural networks to address specific problems or datasets. Here are six. Each has its own advantages and they are presented here roughly in the order of their development, with each successive model adjusting to overcome a weakness in a previous model.
One potential weakness across them all is that deep learning models are often “black boxes,” making it difficult to understand their inner workings and posing interpretability challenges. But this can be balanced against the overall benefits of high accuracy and scalabil Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs)
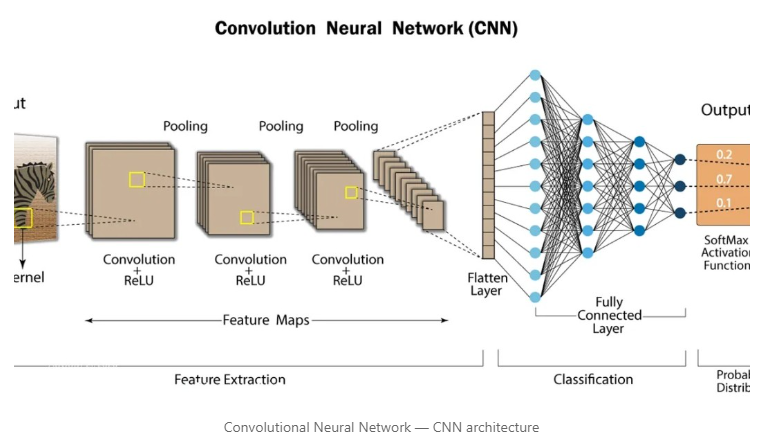
Convolutional Neural Networks (CNNs) are a specialized type of artificial neural network that has revolutionized the field of computer vision and image processing. By leveraging their unique architecture, CNNs are capable of automatically learning hierarchical features from data, making them highly effective for tasks such as image recognition, object detection, and image segmentation. Unlike traditional fully connected networks, CNNs are specifically designed to handle the spatial structure of data, enabling them to process and analyze images with far greater efficiency and accuracy.
How CNNs Work
CNNs process data in a way that mimics how the human brain interprets visual information. They are particularly adept at detecting local patterns, such as edges, textures, and shapes, within images. The primary components of a CNN include:
- Convolutional Layers:
- The convolutional layer is the cornerstone of CNNs. It performs the convolution operation, where small, learnable filters (or kernels) slide over the input data to create feature maps.
- Each filter extracts different features from the input, such as edges or textures, allowing the network to learn spatial hierarchies of features.
- Stride (the step size of the filter) and padding (adding extra pixels around the input to maintain dimensionality) are often used to control how the filter moves over the input.
- Activation Functions:
- Non-linear activation functions, like ReLU (Rectified Linear Unit), are applied after the convolution operation to introduce non-linearity and allow the network to learn more complex patterns.
- ReLU is defined as f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x), which helps the model train faster by avoiding the vanishing gradient problem prevalent in deep networks.
- Pooling Layers:
- Pooling layers reduce the dimensionality of feature maps while retaining important information. This helps decrease the number of parameters and computational cost, making the network more efficient.
- Max pooling is the most common pooling operation, where the maximum value from each region of the feature map is selected.
- Average pooling can also be used, which takes the average of each region.
- Fully Connected Layers:
- After the convolutional and pooling layers, the network is typically flattened and passed through one or more fully connected layers (similar to those in a traditional neural network).
- These layers combine the extracted features to make the final decision or prediction.
- Output Layer:
- The output layer uses an activation function like Softmax for multi-class classification or Sigmoid for binary classification to generate the final predictions.
Hierarchical Feature Learning
One of the main strengths of CNNs is their ability to learn features hierarchically:
- Lower Layers: Learn basic features like edges and corners.
- Middle Layers: Learn more complex patterns such as shapes or parts of objects.
- Higher Layers: Learn abstract features that are closer to the complete representation of objects.
This hierarchical feature extraction allows CNNs to generalize well to various tasks and makes them highly effective in recognizing and interpreting visual information.
Recurrent Neural Networks (RNNs)

Recurrent Neural Networks (RNNs) are a class of neural networks designed for processing sequential data, making them well-suited for tasks where context and order are important. Unlike feedforward neural networks, RNNs have loops within their architecture that allow information to persist, enabling them to maintain a memory of previous inputs. This capability allows RNNs to be applied to tasks involving time series data, natural language processing (NLP), and any situation where data has a sequential dependency.
RNNs are structured in a way that each neuron, or node, is connected not only to the next layer but also to itself in the next time step. This recurrent connection allows data from earlier time steps to influence the current output, making RNNs effective for learning temporal dependencies.
How RNNs Work
The unique characteristic of RNNs is their recurrent loop, which feeds the output of a neuron back into the network as input for the next step. This cycle allows the network to maintain a hidden state that captures information about the sequence up to the current time step.
Key components of RNNs include:
- Input Layer: Receives the input sequence data.
- Hidden Layers: The core of RNNs, where the recurrent connections reside. The hidden state at each time step acts as the memory of the network, storing information from the previous time steps.
- Output Layer: Generates the output for each time step, which could be a classification, regression, or another type of prediction.
Forward Propagation in an RNN works by passing inputs through the network while maintaining the hidden state that gets updated with each time step. Backpropagation Through Time (BPTT) is used for training RNNs, where gradients are propagated backward through each time step to adjust the weights.
Variants of RNNs
Standard RNNs often struggle with learning long-term dependencies due to problems like the vanishing gradient. To address these issues, more sophisticated variants have been developed:
- Long Short-Term Memory Networks (LSTMs): Designed with special gating mechanisms (input gate, output gate, and forget gate) that allow them to retain or forget information selectively. This helps LSTMs capture longer dependencies and avoid the vanishing gradient problem.
- Gated Recurrent Units (GRUs): A simplified version of LSTMs that combines the forget and input gates into a single update gate, reducing complexity while still capturing long-term dependencies effectively.
Advantages of RNNs
- Sequential Data Processing: RNNs are inherently suited for tasks involving sequential data, such as time series analysis, speech recognition, and language modeling.
- Memory of Previous Inputs: The architecture’s recurrent connections enable RNNs to maintain a memory of past information, allowing them to make predictions based on the sequence of prior data.
- Versatility: RNNs can handle inputs and outputs of varying lengths, making them flexible for tasks like translation, where the length of the input and output sequences can differ.
- Temporal Pattern Recognition: The hidden state allows RNNs to recognize patterns over time, making them ideal for applications such as stock market prediction and audio processing.
Disadvantages of RNNs
- Vanishing and Exploding Gradient Problem: When training RNNs, gradients may diminish (vanish) or grow exponentially (explode) as they are propagated back through many time steps, which can lead to unstable training and poor performance.
- Difficulty with Long-Term Dependencies: Standard RNNs struggle to capture dependencies that span over many time steps due to the vanishing gradient problem, which limits their effectiveness for complex, long-sequence tasks.
- Computational Complexity: Training RNNs can be computationally intensive, especially for long sequences, due to their sequential nature and the need to process one time step at a time.
- Training Time: The recurrent connections and complex backpropagation make training slower compared to simpler feedforward networks.
- Lack of Parallelism: Unlike other types of neural networks, RNNs process sequences step-by-step, which limits the use of parallel computation and increases training time.
Autoencoders
Autoencoders are a type of artificial neural network designed for unsupervised learning tasks, primarily used for dimensionality reduction, data compression, and feature learning. They were first introduced in the 1980s as a means to learn efficient codings of input data, but they have since evolved to become a critical component in various applications within deep learning.
At their core, autoencoders work by learning to replicate their input to their output through a bottleneck structure. This unique architecture forces the model to learn a compressed representation of the input, known as the latent space or encoded representation. The goal of the autoencoder is not just to copy the input perfectly, but to learn the most significant features of the input data that allow for an accurate reconstruction. This capability makes autoencoders particularly useful for tasks like anomaly detection, image denoising, and even data generation.
An autoencoder consists of two main parts:
- Encoder: Compresses the input data into a smaller, encoded representation by extracting essential features. This stage helps reduce the data dimensionality while preserving the most relevant information.
- Decoder: Reconstructs the original input from the encoded representation. The decoder learns to use the compressed data to generate outputs that closely resemble the original input.
The network is trained by minimizing the difference between the input and the output, typically using a loss function like mean squared error. Through this process, autoencoders become adept at learning latent features that can be used for downstream tasks such as clustering, data visualization, and feature extraction.
Autoencoders come in various forms to suit different purposes:
- Vanilla Autoencoders: The basic type with a simple encoder-decoder structure.
- Denoising Autoencoders: Specifically trained to reconstruct clean outputs from noisy inputs, enhancing robustness.
- Sparse Autoencoders: Introduce sparsity constraints to learn more meaningful features and prevent the network from memorizing the input.
- Variational Autoencoders (VAEs): A probabilistic approach that learns latent variable distributions and can generate new data similar to the training set.
- Convolutional Autoencoders: Utilize convolutional layers, making them well-suited for processing image data and capturing spatial hierarchies.
One of the major advantages of autoencoders is their ability to perform non-linear dimensionality reduction, offering more flexibility and power than traditional methods like Principal Component Analysis (PCA). This allows autoencoders to capture complex patterns and dependencies in high-dimensional data. Despite these strengths, autoencoders can be prone to overfitting and may require careful tuning of hyperparameters and regularization techniques.
In summary, autoencoders are powerful tools in the deep learning toolkit, enabling the efficient encoding of data, noise reduction, and the discovery of hidden structures within complex datasets. Their versatility and ability to adapt to various tasks make them an essential component in modern AI applications, particularly in scenarios where feature extraction and data compression are critical.
GANs
Generative adversarial networks (GANs) are neural networks that are used both in and outside of artificial intelligence (AI) to create new data resembling the original training data. These can include images appearing to be human faces—but are generated, not taken of real people. The “adversarial” part of the name comes from the back-and-forth between the two portions of the GAN: a generator and a discriminator.
- The generator creates something: images, video or audio and then producing an output with a twist. For example, a horse can be transformed into a zebra with some degree of accuracy. The result depends on the input and how well-trained the layers are in the generative model for this use case.
- The discriminator is the adversary, where the generative result (fake image) is compared against the real images in the dataset. The discriminator tries to distinguish between the real and fake images, video or audio.
GANs train themselves. The generator creates fakes while the discriminator learns to spot the differences between the generator’s fakes and the true examples. When the discriminator is able to flag the fake, then the generator is penalized. The feedback loop continues until the generator succeeds in producing output that the discriminator cannot distinguish.
The prime GAN benefit is creating realistic output that can be difficult to distinguish from the originals, which in turn may be used to further train machine learning models. Setting up a GAN to learn is straightforward, since they are trained by using unlabeled data or with minor labeling. However, the potential disadvantage is that the generator and discriminator might go back-and-forth in competition for a long time, creating a large system drain. One training limitation is that a huge amount of input data might be required to obtain a satisfactory output. Another potential problem is “mode collapse,” when the generator produces a limited set of outputs rather than a wider variety.
Transformer models
Transformer models combine an encoder-decoder architecture with a text-processing mechanism and have revolutionized how language models are trained. An encoder converts raw, unannotated text into representations known as embeddings; the decoder takes these embeddings together with previous outputs of the model, and successively predicts each word in a sentence.
Using fill-in-the-blank guessing, the encoder learns how words and sentences relate to each other, building up a powerful representation of language without having to label parts of speech and other grammatical features. Transformers, in fact, can be pretrained at the outset without a particular task in mind. After these powerful representations are learned, the models can later be specialized—with much less data—to perform a requested task.
Several innovations make this possible. Transformers process words in a sentence simultaneously, enabling text processing in parallel, speeding up training. Earlier techniques including recurrent neural networks (RNNs) processed words one by one. Transformers also learned the positions of words and their relationships—this context enables them to infer meaning and disambiguate words such as “it” in long sentences.
By eliminating the need to define a task upfront, transformers made it practical to pretrain language models on vast amounts of raw text, enabling them to grow dramatically in size. Previously, labeled data was gathered to train one model on a specific task. With transformers, one model trained on a massive amount of data can be adapted to multiple tasks by fine-tuning it on a small amount of labeled task-specific data.
Language transformers today are used for nongenerative tasks such as classification and entity extraction as well as generative tasks including machine translation, summarization and question answering. Transformers have surprised many people with their ability to generate convincing dialog, essays and other content.
Natural language processing (NLP) transformers provide remarkable power since they can run in parallel, processing multiple portions of a sequence simultaneously, which then greatly speeds training. Transformers also track long-term dependencies in text, which enables them to understand the overall context more clearly and create superior output. In addition, transformers are more scalable and flexible in order to be customized by task.
As to limitations, because of their complexity, transformers require huge computational resources and a long training time. Also, the training data must be accurately on-target, unbiased and plentiful to produce accurate results.
Deep learning use cases
Deep learning has become a powerful tool across a wide range of industries and applications due to its ability to learn and model complex, high-dimensional data. Here are some of the most significant use cases for deep learning:
1. Computer Vision
- Image Classification: Deep learning models, particularly Convolutional Neural Networks (CNNs), can classify images into categories with high accuracy. Applications include classifying medical images to diagnose diseases or categorizing products in e-commerce.
- Object Detection: Used in self-driving cars, surveillance systems, and robotic vision to identify and locate objects within an image or video.
- Image Segmentation: Helps in medical imaging to delineate organs and tissues, facilitating more precise medical analysis and treatment planning.
- Facial Recognition: Deployed in security systems, smartphone authentication, and social media tagging to identify or verify individuals.
2. Natural Language Processing (NLP)
- Language Translation: Deep learning models, such as transformer architectures, power translation services like Google Translate, enabling real-time and highly accurate language translations.
- Sentiment Analysis: Helps businesses gauge public opinion and sentiment from customer reviews, social media posts, and feedback.
- Text Generation: Models like GPT (Generative Pre-trained Transformer) can generate human-like text, assisting in content creation, chatbots, and customer service automation.
- Speech Recognition: Converts spoken language into text and is used in virtual assistants (e.g., Siri, Google Assistant), transcription services, and automated customer service.
3. Healthcare and Medical Imaging
- Disease Diagnosis: Deep learning algorithms are trained to detect anomalies in X-rays, MRIs, CT scans, and other medical images, helping doctors diagnose diseases such as cancer and neurological conditions more accurately.
- Drug Discovery: Deep learning aids in predicting the interactions of new drugs and their potential side effects, accelerating the drug development process.
- Personalized Medicine: Models analyze genetic information to provide personalized treatment plans based on individual patient data.
4. Autonomous Vehicles
- Self-Driving Cars: Deep learning models process and interpret sensor data (e.g., from cameras, LiDAR, radar) to make real-time driving decisions, detect obstacles, recognize traffic signs, and navigate safely.
- Advanced Driver Assistance Systems (ADAS): Provides features like lane departure warning, adaptive cruise control, and automatic parking.
5. Financial Services
- Fraud Detection: Deep learning models analyze large volumes of transaction data to identify unusual patterns and flag potential fraud.
- Algorithmic Trading: Uses deep learning to analyze market data, recognize patterns, and make trade recommendations or execute trades autonomously.
- Credit Scoring and Risk Management: Helps financial institutions evaluate creditworthiness and predict loan default risks.
6. Recommendation Systems
- Content Recommendation: Platforms like Netflix, YouTube, and Spotify use deep learning to recommend shows, videos, and songs based on user preferences and behavior.
- E-commerce: Online retailers employ recommendation systems to suggest products that users might be interested in, enhancing the shopping experience and increasing sales.
7. Robotics
- Robotic Vision: Deep learning allows robots to process visual data and understand their environment for navigation and manipulation tasks.
- Human-Robot Interaction: Improves the ability of robots to interact naturally with humans, understanding gestures, speech, and expressions.
- Automation: In manufacturing, deep learning is used for quality inspection, predictive maintenance, and process optimization.
8. Gaming and Entertainment
- Game AI: Deep learning powers intelligent NPCs (non-player characters) and adaptive game mechanics.
- Generative AI for Art: Tools like GANs (Generative Adversarial Networks) can create realistic art, music, and animations.
- Content Creation: Deep learning is used to generate unique content for films and video games, from automated animation to realistic character models.
9. Voice Assistants and Smart Home Devices
- Speech Synthesis and Voice Recognition: Deep learning powers the ability of virtual assistants like Amazon Alexa and Google Home to understand and respond to user commands.
- Home Automation: Learns user habits and preferences to automate tasks like adjusting the thermostat, lighting, and security settings.
10. Cybersecurity
- Threat Detection: Deep learning models identify malicious activities and potential security threats by analyzing network traffic and user behavior.
- Spam Filtering: Helps filter out spam emails and detect phishing attacks through natural language understanding.
- Anomaly Detection: Detects unusual patterns in data that could indicate cybersecurity threats.
11. Energy Sector
- Predictive Maintenance: Deep learning models help monitor equipment and predict failures, improving efficiency and reducing downtime.
- Energy Forecasting: Analyzes data to predict energy usage and optimize energy production and distribution.
- Smart Grids: Assists in managing energy flows, identifying faults, and optimizing load distribution in real-time.
12. Agriculture
- Crop Monitoring: Analyzes satellite and drone imagery to monitor crop health and detect issues such as diseases, pest infestations, or inadequate irrigation.
- Yield Prediction: Predicts crop yields based on data from sensors and historical trends.
- Precision Farming: Optimizes the use of resources like water, fertilizers, and pesticides to improve efficiency and productivity.
13. Customer Service
- Chatbots: Deep learning powers conversational AI that can understand and respond to customer queries, providing support 24/7.
- Sentiment Analysis: Analyzes customer feedback to understand sentiments and improve service delivery.
- Automated Ticket Routing: Prioritizes and routes customer issues to the appropriate support teams based on the nature of the query.
14. Astronomy and Space Exploration
- Space Object Detection: Assists in identifying and tracking celestial bodies, asteroids, and potential space debris.
- Exoplanet Discovery: Analyzes data from telescopes to identify new planets outside our solar system.
- Satellite Image Analysis: Processes satellite imagery for environmental monitoring, weather prediction, and disaster response.
15. Generative AI
- Image and Video Generation: Models like GANs can create realistic images and videos that can be used in marketing, film production, and virtual reality.
- Text Generation: Creates human-like text for applications in content creation, dialogue systems, and writing assistants.
- Deepfakes: Although controversial, deep learning is used to create hyper-realistic altered videos and images for entertainment or educational purposes.
Summary
Deep learning has a diverse range of applications that continue to grow as the field evolves. Its ability to learn from and adapt to complex data structures makes it a powerful tool for solving problems across industries. From enhancing medical diagnostics to improving customer experiences, deep learning is a cornerstone of modern AI innovation.
Challenges and Limitations
6.1 Data Dependency
Deep learning requires vast amounts of data to perform optimally, making it challenging in scenarios with limited data availability.
6.2 Computational Resources
Training deep learning models demands significant computational power, often necessitating specialized hardware like GPUs and TPUs.
6.3 Interpretability
Deep learning models are often considered “black boxes,” making it difficult to interpret how decisions are made.
7. Future Trends in Deep Learning
- Generative AI: With models like GANs (Generative Adversarial Networks) creating realistic images and deepfakes, generative AI is pushing creative boundaries.
- Multimodal Learning: Combining data from multiple sources, such as text and images, to enhance understanding and prediction.
- Edge AI: Running deep learning algorithms on edge devices to reduce latency and enable real-time data processing.
- Explainable AI: Research into making deep learning models more transparent and interpretable.
Conclusion
Deep learning continues to revolutionize industries by providing innovative solutions to complex problems. Despite its challenges, advancements in data, computation, and algorithms are propelling the field toward even more groundbreaking discoveries.