Integrating Big Data and AI – Training AI Models at Scale 2024
http://Integrating Big Data and AI – Training AI Models at Scale 2024
Introduction
The rapid growth of data in today’s digital world demands new strategies to harness its potential. The integration of big data with artificial intelligence (AI) offers unparalleled opportunities for businesses and researchers to gain insights, make data-driven decisions, and build advanced AI solutions. Big data technologies enable scalable, efficient, and high-performance processing of massive datasets, which are essential for training sophisticated machine learning (ML) and deep learning (DL) models.
In this detailed guide, we’ll explore the interplay between big data and AI, focusing on the tools and best practices for training AI models at scale. We will delve into key technologies such as Hadoop, Apache Spark, and Apache Flink, and how they contribute to scalable AI model training.
1. <a href="http://<!– wp:heading {"level":4} –> <h4 class="wp-block-heading">1. Core Concepts of Big Data and AI Integration</h4> Core Concepts of Big Data and AI Integration
Big Data Characteristics:
- Volume: Enormous quantities of data generated from multiple sources, such as IoT devices, social media, and transactional records.
- Variety: Diverse data types, including structured, semi-structured, and unstructured data.
- Velocity: High speed at which data is generated and needs to be processed.
- Veracity: Ensuring the accuracy and trustworthiness of data.
- Value: Extracting meaningful insights from raw data.
AI’s Role: AI leverages big data for training models that can predict outcomes, classify data, and make autonomous decisions. The integration aims to:
- Enhance predictive accuracy by using comprehensive datasets.
- Improve the training process with faster, distributed data processing.
- Optimize resource utilization through parallel computing.
2. Essential Tools for Training AI Models with Big Data

a. Apache Hadoop
Apache Hadoop is one of the foundational frameworks for big data processing. It provides a distributed computing environment that handles vast amounts of data across clusters of machines.
Components:
- HDFS (Hadoop Distributed File System): Ensures data is stored redundantly across clusters.
- MapReduce: A programming model for processing large-scale data using a divide-and-conquer strategy.
- YARN: Manages resources in the Hadoop ecosystem.
Advanced Use Case: Training models by pre-processing large-scale data with MapReduce, converting raw data into training-ready formats, and integrating with downstream ML frameworks.
HTML Code Example for Data Aggregation:
public static class AverageMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable valueOut = new IntWritable();
private Text wordOut = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] tokens = value.toString().split(",");
wordOut.set(tokens[0]);
valueOut.set(Integer.parseInt(tokens[1]));
context.write(wordOut, valueOut);
}
}
public static class AverageReducer extends Reducer<Text, IntWritable, Text, DoubleWritable> {
private DoubleWritable result = new DoubleWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
for (IntWritable val : values) {
sum += val.get();
count++;
}
result.set((double) sum / count);
context.write(key, result);
}
}
b. Apache Spark
Apache Spark has transformed the field of big data processing with its ability to process data in-memory. This allows for faster data computation compared to Hadoop’s disk-based MapReduce.
Features:
- Spark Core: Handles basic functions like task scheduling and memory management.
- Spark SQL: Provides SQL-like capabilities for querying structured data.
- Spark MLlib: A machine learning library that supports clustering, classification, regression, and collaborative filtering.
- Streaming Capabilities: Supports real-time data processing with Spark Streaming.
HTML Code Example for Machine Learning Pipeline:
import org.apache.spark.ml.feature.VectorAssembler;
import org.apache.spark.ml.regression.LinearRegression;
// Load and transform data
Dataset<Row> data = spark.read().format("libsvm").load("data/sample_linear_regression_data.txt");
VectorAssembler assembler = new VectorAssembler().setInputCols(new String[]{"feature1", "feature2"}).setOutputCol("features");
Dataset<Row> assembledData = assembler.transform(data);
// Train model
LinearRegression lr = new LinearRegression().setLabelCol("label");
LinearRegressionModel model = lr.fit(assembledData);
System.out.println("Coefficients: " + model.coefficients() + " Intercept: " + model.intercept());
c. Apache Flink
Apache Flink stands out for its real-time stream processing capabilities. It is highly suitable for applications where real-time insights and continuous processing are critical.
Benefits:
- Low Latency: Processes events in near real-time.
- Event Time Processing: Manages out-of-order events based on their actual timestamps.
- Batch and Streaming in One: Combines the power of batch and streaming data processing.
HTML Code Example for Real-Time Streaming:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> stream = env.readTextFile("input.txt");
stream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
for (String word : value.split(" ")) {
out.collect(new Tuple2<>(word, 1));
}
}
}).keyBy(0).sum(1).print();
env.execute("Real-Time Word Count");
3. Integrating Big Data and AI: Architecture and Pipelines
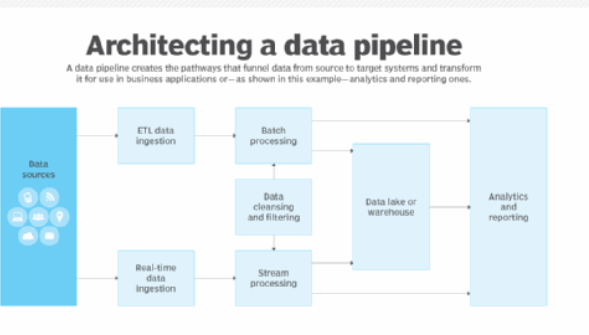
To effectively integrate big data tools with AI, it is essential to build data pipelines that support data ingestion, processing, and training phases:
- Data Ingestion: Use Hadoop HDFS or cloud-based storage solutions to collect and store raw data.
- Batch Processing: Leverage Apache Spark for cleaning, transforming, and aggregating data for large-scale ML training.
- Real-Time Processing: Utilize Apache Flink to stream data in real time, enabling continuous model training and real-time predictions.
- Model Training and Evaluation: Deploy Spark MLlib or external ML frameworks such as TensorFlow on Spark to train models in a distributed manner.
- Model Serving: Integrate with tools like Apache Kafka for streaming data pipelines that serve real-time AI predictions.
Data Pipeline Code Snippet for Big Data and AI Integration (HTML format):
<pre><code>
import org.apache.spark.sql.SparkSession;
import org.apache.flink.api.java.ExecutionEnvironment;
// Spark setup for batch processing
SparkSession spark = SparkSession.builder().appName("AI Big Data Integration").getOrCreate();
Dataset<Row> batchData = spark.read().json("hdfs://data/input.json");
// Flink setup for real-time streaming
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataStream<String> realTimeData = env.fromElements("data1", "data2", "data3");
// Process data with Spark and train an AI model
batchData.createOrReplaceTempView("training_data");
Dataset<Row> processedData = spark.sql("SELECT * FROM training_data WHERE value > threshold");
// Train the AI model here
</code></pre>
4. Real-World Applications of Big Data and AI Integration
- Healthcare: Using big data for patient data analysis and training AI for diagnostic predictions.
- Finance: Analyzing real-time market trends and training algorithms for fraud detection.
- Retail: Leveraging customer data for personalized recommendations and inventory management.
- Manufacturing: Utilizing IoT-generated data for predictive maintenance and quality assurance.
5. Benefits and Best Practices
- Scalability: By distributing data processing across nodes, big data tools ensure that large-scale training is possible without performance bottlenecks.
- Real-Time Adaptation: Apache Flink’s real-time processing capabilities allow models to learn from incoming data and adapt quickly.
- Resource Management: Using cluster management tools like YARN and Kubernetes ensures optimal resource allocation.
Best Practices:
- Data Partitioning: Split data into manageable chunks to improve parallel processing.
- Caching: Use Spark’s caching mechanisms to store intermediate data for faster computations.
- Checkpointing: Implement checkpoints in streaming pipelines for fault tolerance.
6. Challenges and Solutions
- Data Quality: Ensure data preprocessing pipelines are robust to handle diverse data formats.
- Resource Constraints: Optimize job execution using Spark’s in-memory processing and Flink’s event-driven execution.
- Integration Complexity: Leverage container orchestration tools like Docker and Kubernetes for smoother deployment of distributed AI systems.The Benefits of Using Big Data and AI Together
- The combination of Big Data and AI offers a plethora of benefits for businesses that embrace these cutting-edge technologies. This powerful synergy is transforming traditional business operations and propelling organizations toward unparalleled productivity and success. Let’s check the prerequisites for these improved results:
The Benefits of Using Big Data and AI Together
The combination of Big Data and AI offers a plethora of benefits for businesses that embrace these cutting-edge technologies. This powerful synergy is transforming traditional business operations and propelling organizations toward unparalleled productivity and success. Let’s check the prerequisites for these improved results:
Conclusion
The integration of big data technologies with AI represents a powerful paradigm shift in data-driven decision-making and intelligent automation. Tools like Hadoop, Apache Spark, and Apache Flink empower data scientists and engineers to harness massive datasets, process them efficiently, and train scalable AI models. By understanding the core principles and best practices outlined here, organizations can effectively implement big data and AI solutions that unlock new levels of performance and innovation.